Five years on, the Open Science-driven journal Research Ideas and Outcomes (RIO) published an editorial that looks back on the 300 research ideas and research outcomes it has published so far.
Since its early days, RIO has enjoyed quite positive reactions from the open-minded academic community for its innovative approach to Open Science in practice: it provides a niche that had long been missing, namely the publication of early, intermediate and generally unconventional research outcomes from all around the research cycle (e.g. grant proposals, data management plans, project deliverables, reports, policy briefs, conference materials) in a cross-disciplinary scientific journal. In fact, several months after its launch, in 2016, the journal was acknowledged with the SPARC Innovator Award.
‘Alternative’ research publications
In times when posting a preprint was seen as a novel and rather bold practice across many fields, RIO facilitated much deeper dives into the research process, in order to unveil scientific knowledge and the process by which it is gathered, well before any final conclusions have been drawn. Long story short, to date, RIO has published 33 Research Ideas, 78 Grant Proposals, 16 Data Management Plans, 33 Workshop Reports and 5 PhD Project Plans, in addition to plenty of other early, interim and final non-traditional research outcomes, as well as conventional articles. Over time, RIO has kept adding additional article types to its list of publication types, with a few more expected in the near future.
What’s more, over the years, we’ve already observed how papers published in RIO successfully followed up on the continuity of the research process. For example, the Grant Proposal for the “Exploring the opportunities and challenges of implementing open research strategies within development institutions” project, funded by the International Development Research Centre (IDRC), was followed by the project’s Data Management Plan a year later.
Five years later, the figures reflecting the usage and engagement with the content published in RIO are evidently supportive of the value of having non-final and unconventional academic publications. For instance, the Grant Proposal for the COST Action DNAqua-Net, a still ongoing project dedicated to the development of novel genetic tools for bioassessment and monitoring of aquatic ecosystems, is the article with the most total views in RIO’s publication record to date. In the category of sub-article elements, whose usage is also tracked at the journal, the most viewed figure belongs to a Project Report and illustrates a sample code meant to be used in future neuroimaging studies. Similarly, the most viewed table ever published in RIO is part of a Workshop Report that summarises ASAPbio‘s third workshop, dedicated to the technical aspects of services related to the promotion of preprints in the biomedical and other life science communities.
Response to societal challenges
A unique and defining staple for RIO since the very beginning has also been the pronounced engagement with the Sustainable Development Goals (SDGs), as formulated by the United Nations right around the time of RIO’s launch. In order to highlight the societal impact of published research, RIO lets authors map their articles to the SDGs relevant to their paper. Once published, the article displays the associated badge(s) next to its title. Readers of the journal can even search RIO’s content by SDG, in the same way they would filter articles by subject, publication types, date or funding agency. Next on the list for RIO is to add another level of granularity to the SDGs mapping. The practice has already been piloted by mapping relevant RIO articles to the ten targets under SDG14 (Life below water).
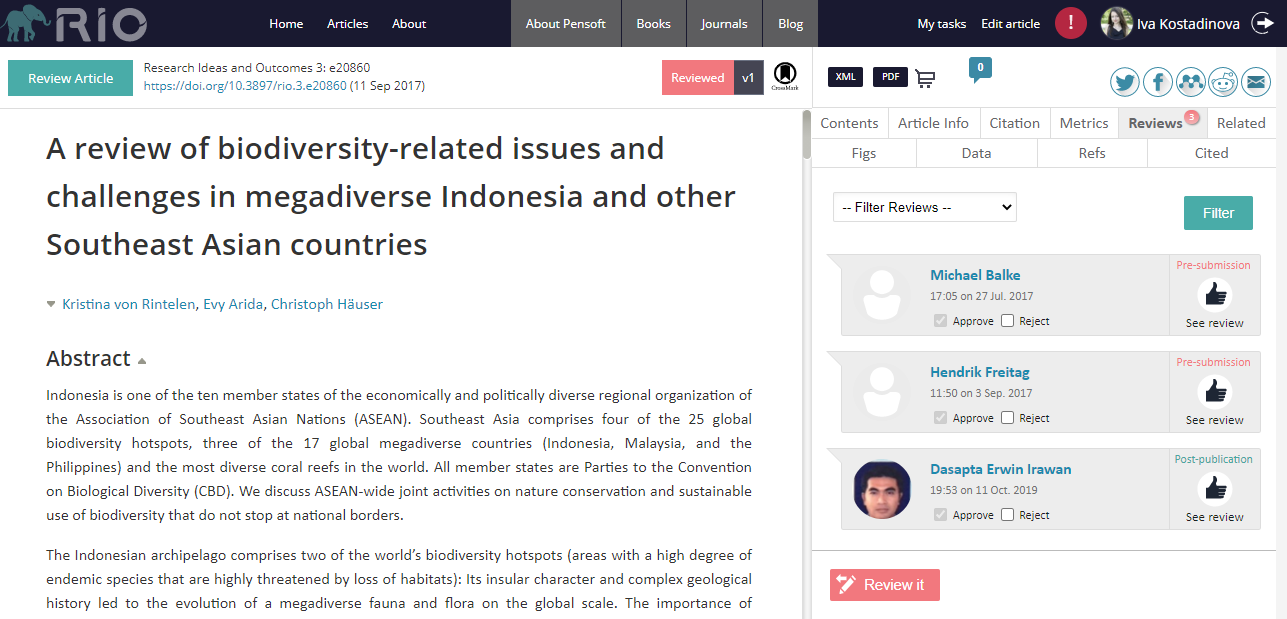
Taking transparency, responsibility and collaboration in academia and scholarly publishing up another notch, RIO requires for reviews to be publicly available. In addition, the journal supports post-publication reviews, where peers are free to post their review anytime. In turn, RIO registers each review with its own DOI via CrossRef, in order to recognise the valuable input and let the reviewers easily refer to their contributions. A fine example is a Review Article exploring the biodiversity-related issues and challenges across Southeast Asia, which currently has a total of three public peer reviews, one of which is provided two years after the publication of the paper.
Public, transparent and perpetual peer review, pre- and/or post-publication
What’s more striking about peer review at RIO, however, is that it is not always mandatory. Given that the journal publishes many article types that have already been scrutinised by a legitimate authority – for instance, Grant Proposals that have previously been evaluated by a funder or defended PhD Theses – it only makes sense to avoid withholding these publications and duplicating associated evaluation efforts. On such occasions, all an author needs to do is provide a statement about the review status of their paper, which will be made public alongside the article.
On the other hand, where the article type of a manuscript requires pre-publication review, to avoid potential delays caused by the review process and editorial decisions, RIO encourages the authors to post their pre-review manuscript as a preprint on the recently launched ARPHA Preprints platform, subject to a quick editorial screening, which would only take a few days.
Further, RIO has now abandoned the practice of burdening the journal’s editors with the time-consuming task of finding reviewers, and instead requiring the submitting author to invite suitable reviewers upon submission, who are then immediately and automatically invited by the system. While significantly expediting the editorial work on a manuscript, this practice doesn’t compromise the quality of peer review in the slightest, since the reviews go public, while the final decision about the acceptance of the paper lies with the editor, who is also overlooking the process and able to intervene and invite additional reviewers anytime, if necessary.
Project-driven knowledge hub
The most significant novelty at RIO, however, is perhaps the newly assumed role of the journal as “a project-driven knowledge hub“, targeting specifically the needs of research projects, conference organisers and institutions. For them, RIO provides a one-stop source for the outputs of their scientists, in order to comply with the requirements of their funders or management, or simply to facilitate the discoverability, reusability and citability of their academic outputs and to highlight their interconnectedness.
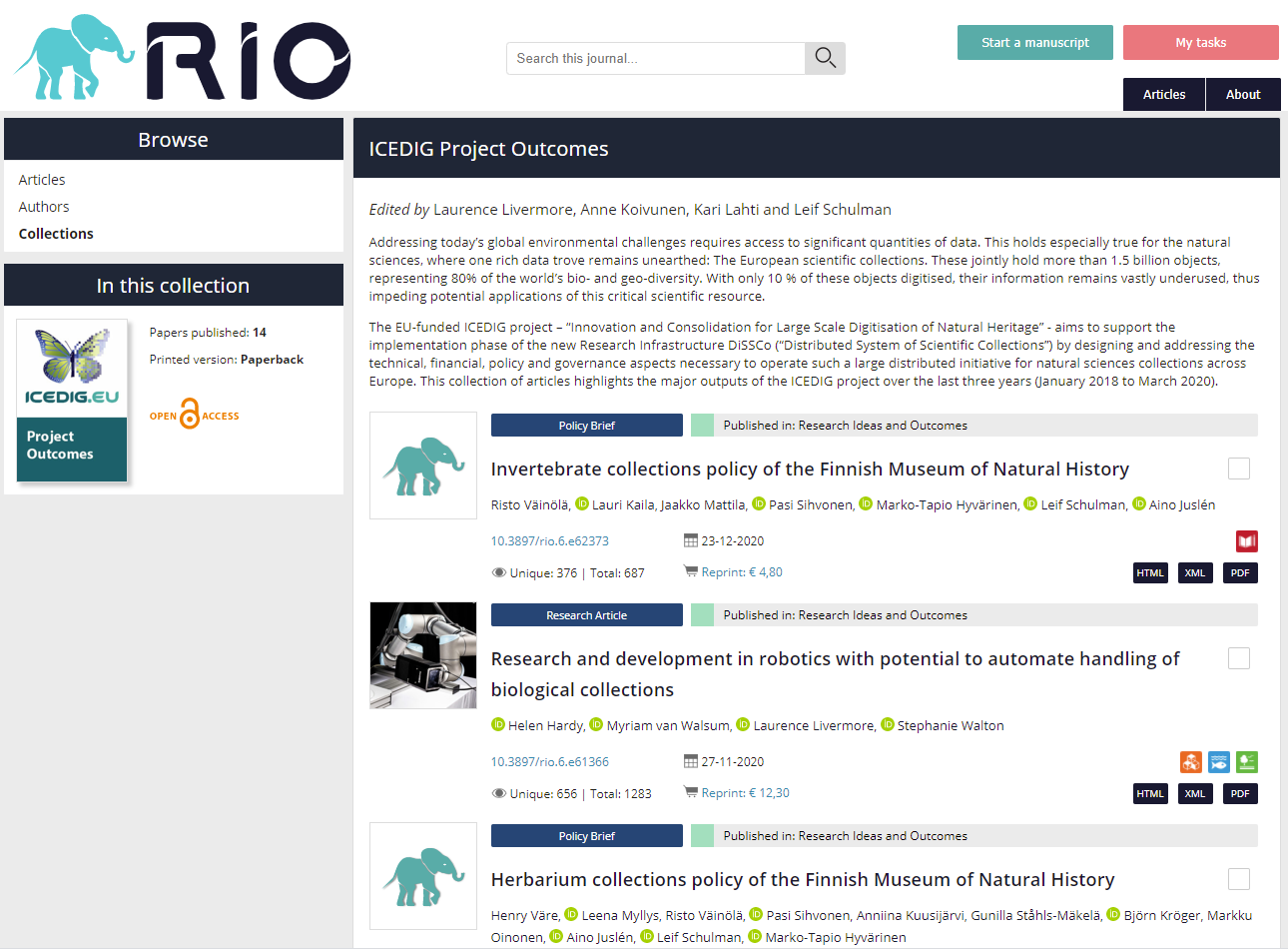
Unlike typical permanent article collections, already widely used in scholarly publishing, with RIO, collection owners can take advantage of the unique opportunity to add a wide range of research outputs, including such published elsewhere, in order to provide even greater context to the assembled research outputs in their project- or institution-branded article collection (see the Horizon 2020 Project Path2Integrity‘s project collection as an example).

For example, a project coordinator could open a collection under the brand of the project, and start by publishing the Grant Proposal, followed shortly by Data and Software Management Plans and Workshop Reports. Thus, even at this early point in the project’s development, the funder – and with them everyone else – would already have strong evidence of the project’s dedication to transparency and active science communication. Later on, the project’s participants would all be able to easily add to the project’s collection by either submitting their diverse research outputs straight to RIO and having it accepted by the collection lead editor, or providing metadata and link to their publication from elsewhere, even preprints. If the document is published outside of RIO, its metadata, i.e. author names and affiliations, article title and publication date, show up in the collection, while a click on the item will lead to the original publication. As the project progresses, the team behind it could add more and more outputs (e.g. Project Reports, Guidelines and Policy Briefs), continuously updating the public and the relevant stakeholders about the development of their work. Eventually, the collection will be able to provide a comprehensive and fully transparent report of the project from start to finish.
###
Follow RIO Journal on Twitter, Facebook and LinkedIn.
Subscribe to RIO Journal’s blog for news updates.